Grok 4 懶人包 | Grok 4 功能Benchmark 表現
xAI 最新推出的 Grok 4 在全球掀起熱潮,號稱是「全球最強 AI 模型」,不僅在各項基準測試(benchmark)中大勝對手,還帶來一堆超強功能,讓人直呼:這 AI 會不會真的要超越人類了?😱 今天就來為大家整理一個 Grok 4 懶人包,帶大家快速搞懂這款 AI 神器的亮點、功能、價格,以及它對未來的影響。
這次 xAI 的目標很明確:打造一個能挑戰 OpenAI、Google 和 Anthropic 等巨頭的 AI 模型。從目前的 benchmark 表現來看,Grok 4 確實有這個實力!不論是數學、科學、程式設計,還是通用智能測試,Grok 4 幾乎全面碾壓對手,甚至被 Elon Musk 誇為「博士級水平」的 AI。
Grok 4 的核心亮點:為什麼這麼強?
Grok 4 的 Benchmark 表現
如何使用Grok 4 ?
Grok 4 的實際應用:你可以用它做什麼?
Grok 4 的核心亮點:為什麼這麼強?
超人類智力表現(超越研究生水平):Grok-4 在「人類期末考試」(Humanity's Last Exam)等多項高難度基準測試中表現出色,這些測試涵蓋數學、科學、人文學科和工程學。它在所有學科中都能達到或超越博士生水平的表現,甚至能指出問題中的錯誤或歧義。
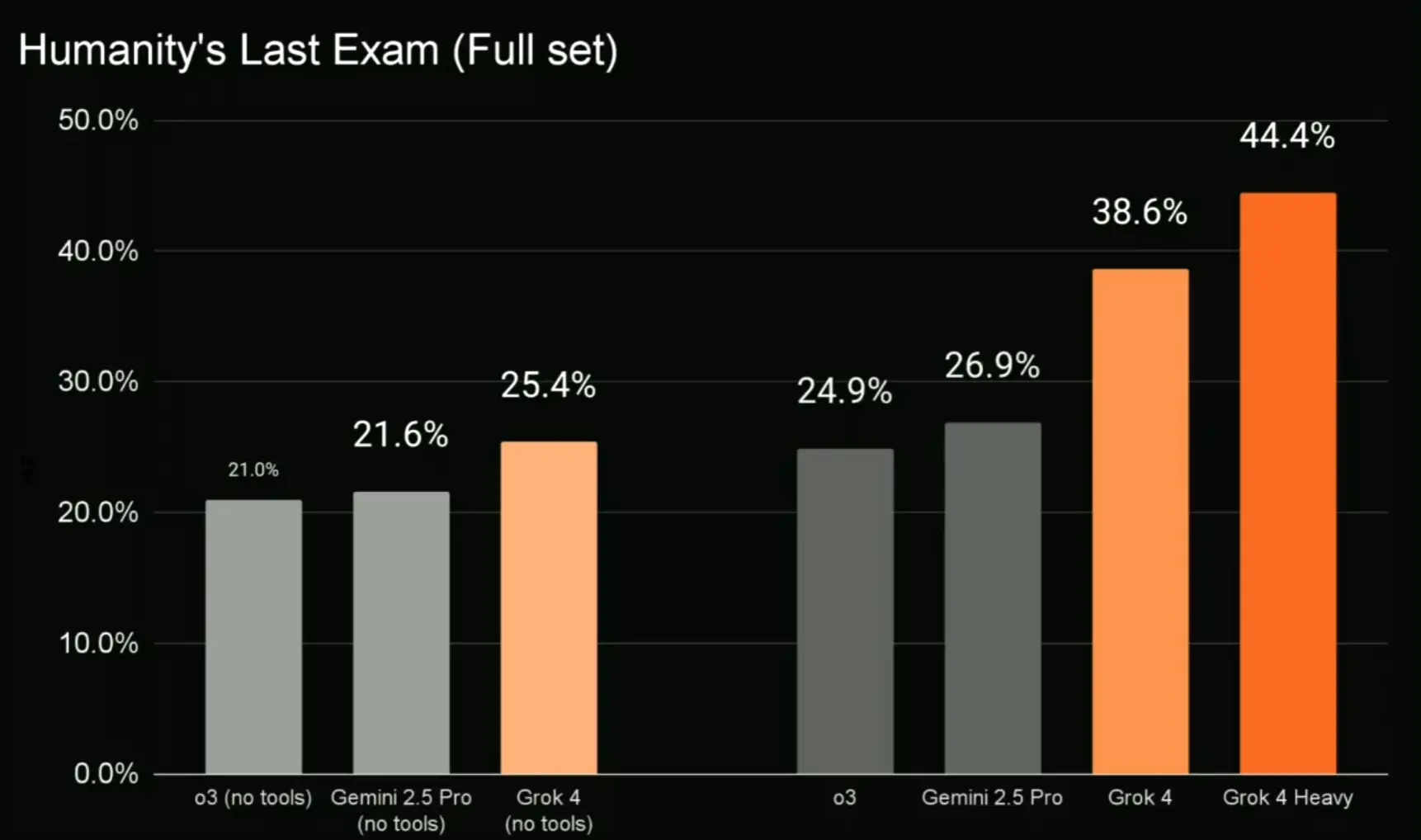
source: XAI
卓越的工具使用能力:與先前的模型相比,Grok-4 Heavy (多代理版本) 能夠更有效地利用外部工具。在訓練中整合工具使用,使其能解決比沒有工具時多一倍的文字問題,這在實際應用中至關重要。
多代理協作能力(Grok-4 Heavy):Grok-4 Heavy 允許多個 AI 代理並行工作。這些代理獨立解決問題,然後互相比較、分享見解並協商出最佳答案,顯著提高了問題解決的準確性和深度。
專為開發者設計的 Grok 4 Code 版本: 能提供智能程式碼補全、除錯和優化建議。只需要把你的程式碼複製貼上到 grok.com,Grok 4 就能幫你找出 bug、改進程式碼,還會詳細解釋問題出在哪裡,比許多程式編輯器還好用!科學研究自動化:Grok-4 已經被用於領先的生物醫學研究中心,如 Arc Institute,以自動化研究流程。它能迅速篩選數百萬個實驗日誌,識別最佳假設,例如在 CRISPR 研究中的應用,大大加速了科學發現。
遊戲和內容創作潛力:Grok-4 能夠在短短 4 小時內從零開始製作出第一人稱射擊遊戲,它能自動化遊戲中的資產(如紋理)和 3D 模型獲取。這表明其在未來遊戲開發和內容創作方面有巨大潛力,讓開發者能更專注於核心創意。
優化的高效語音模式:Grok-4 的語音模式在回應速度上比以前的版本快 2 倍,並提供了 5 種不同的高品質、自然發音的聲音選項。這顯著提升了用戶互動體驗。
API 接口與未來發展:Grok-4 已透過 API 接口開放給開發者使用,實現了更高的自動化水平。未來計畫包括推出專門的編碼模型(8 月)、多模態代理(9 月)和視訊生成模型(10 月),這些都將極大地擴展其應用範圍和能力。
高效訓練:背後的超算神器:Grok 4 的強大離不開 xAI 的 Colossus 超算,這台超級電腦擁有 34 萬顆 GPU,為 Grok 4 提供了 10 倍於 Grok 3 的訓練算力。這種硬核硬件支援讓 Grok 4 的推理能力大幅提升,處理速度也更快。
Grok 4 的 Benchmark 表現
Grok 4 在多項基準測試中表現亮眼,幾乎全面領先競爭對手。以下是幾個關鍵數據,讓你看看它的實力有多強:
- AIME 2025(數學):Grok 4 得分 98.8%,Grok 4 Heavy 100%,遠超 OpenAI o3(98.4%)、Gemini 2.5 Pro(88%)和 Claude 4 Opus(75.5%)。
- GPQA(科學):Grok 4 得分 87.5%,Grok 4 Heavy 88.9%,領先 Claude 4 Opus(79.6%)和 OpenAI o3(83.3%)。
- LiveCodeBench(程式設計):Grok 4 及 Grok 4 Heavy 得分 79.3%-79.4%,完勝 Gemini 2.5 Pro(74.2%)和 OpenAI o3(72%)。
- ARC-AGI v2(通用智能):Grok 4 得分 15.9%,遠超 Claude Opus(8.6%)和 Gemini 2.5 Pro(4.9%)。
- HLE(高階評估):Grok 4 在配備工具時得分 41%,比 Claude Opus 4(35.7%)和 Gemini 2.5 Pro(41%)更強。
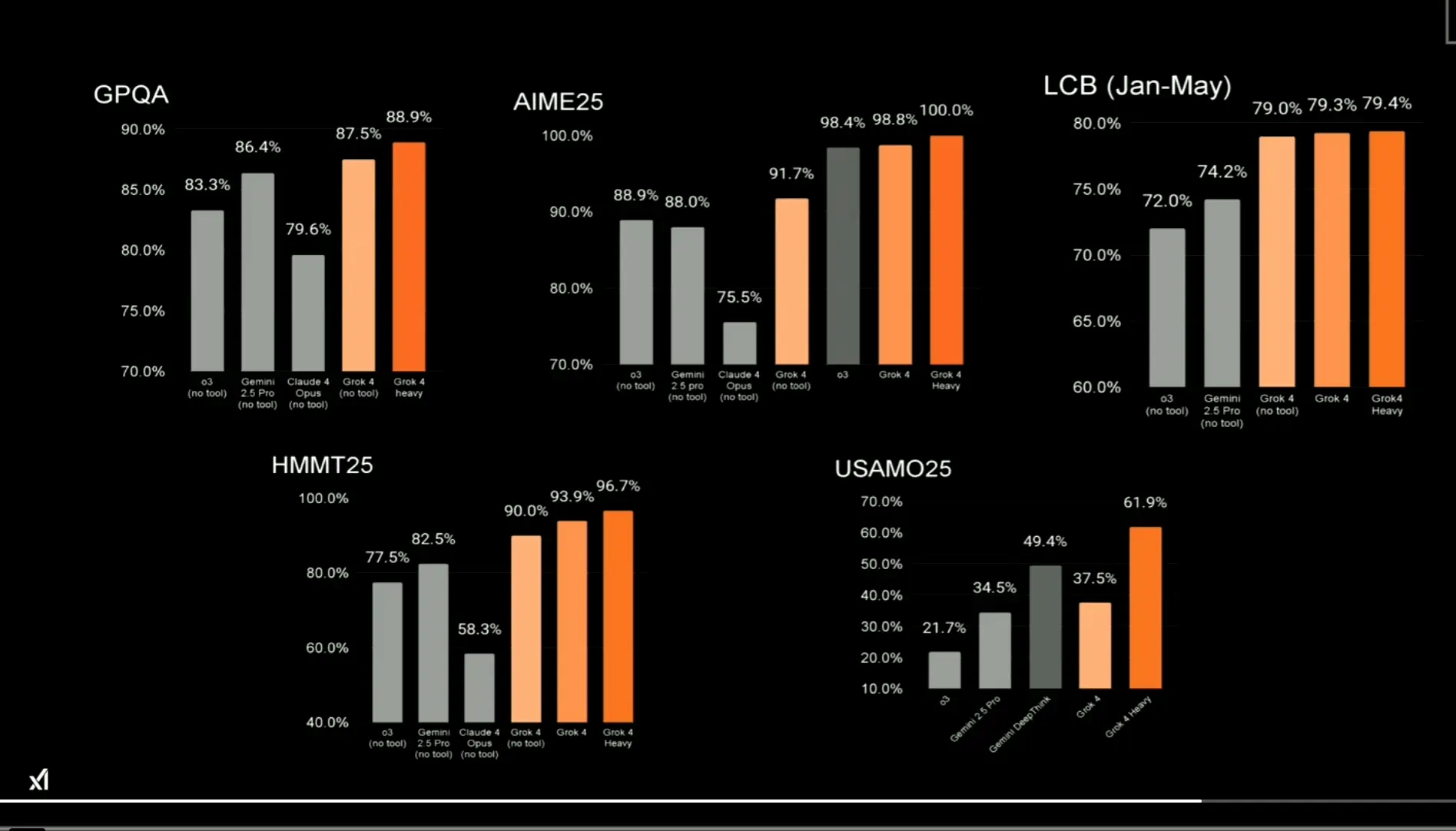
source: XAI
尤其值得一提的是,Grok 4 在 Humanity Last Exam (HLE) 測試中拿下 45% 的高分,遠超其他模型。這項測試被認為是衡量 AI 接近人類思維的重要指標,Grok 4 的表現讓人不禁懷疑:AI 真的要超越人類了嗎?😱 不過,也有聲音質疑 HLE 測試題可能外洩,這點還有待進一步驗證。
AI應用測驗 | 測試你的AI知識
開始





如何使用Grok 4 ?
目前,Grok 4 的完整功能需要訂閱 xAI 的 SuperGrok Heavy 計劃,月費高達 $300,算是 AI 市場中最貴的訂閱之一。普通 SuperGrok 計劃則為 $30/月,提供基礎功能和部分進階功能。雖然價格不低,但對於需要高性能 AI 的開發者或企業來說,Grok 4 的強大推理能力和程式碼優化功能可能物超所值。
希望未來推出免費額度,讓更多人能體驗 Grok 4 的魅力。
Grok 4 的實際應用:你可以用它做什麼?
Grok 4 的應用場景非常廣泛,無論你是學生、開發者還是企業用戶,都能找到它的用武之地:
- 商業模擬 (VendingBench):在模擬經營販賣機業務的 VendingBench 測試中,Grok-4 能夠制定策略、管理庫存、簽訂合約和設定價格,並在長時間運行中表現出色,實現了資產淨值翻倍,證明了其在現實世界商業場景中的應用潛力。
- 科學研究 (與 Arc Institute 合作):Grok-4 已經被領先的生物醫學研究中心 Arc Institute 用於自動化研究流程。它能夠在幾秒鐘內篩選數百萬個實驗日誌,並識別最佳假設,例如在 CRISPR 研究中。
- 遊戲開發:Grok-4 能夠在短短 4 小時內製作出第一人稱射擊遊戲,它能夠自動化遊戲中的資產(如紋理)和 3D 模型獲取,讓開發者可以專注於核心遊戲邏輯。未來,Grok-4 預計將能夠玩遊戲、評估遊戲的趣味性,甚至創建完整的 3D 遊戲。
- 多代理系統 (Grok-4 Heavy):Grok-4 Heavy 允許多個 AI 代理並行工作,它們獨立完成任務,然後比較結果並協商出最佳答案。這種協作能力顯著提高了問題解決的準確性。
AI 快要超越人類了嗎?
看到 Grok 4 的強大表現,很多人開始擔心 AI 會不會有一天真的超越人類智能?答案很複雜,但 Grok 4 的出現無疑讓這個問題更值得思考。它的首次原理推理、多模態功能、即時數據處理和高效訓練,讓它在某些領域的表現已經接近甚至超過人類專家。更重要的是,Grok 4 還在持續進化,xAI 承諾未來會有更多功能推出,AI 的未來真的無可限量!
但別太擔心,Grok 4 目前還是專為高階需求設計的,對於一般用戶來說,它更像是個超聰明的助手,能幫你解決問題、提升效率。記得,AI 只是工具,真正的創造力和決策還是在你手上!🚀
聯繫我們
Whatsapp聯絡我們 :  / 查詢+852 59216804
/ 查詢+852 59216804
*有關參考數字只供參考,數字實際情況可能有所不一樣